


Project Overview
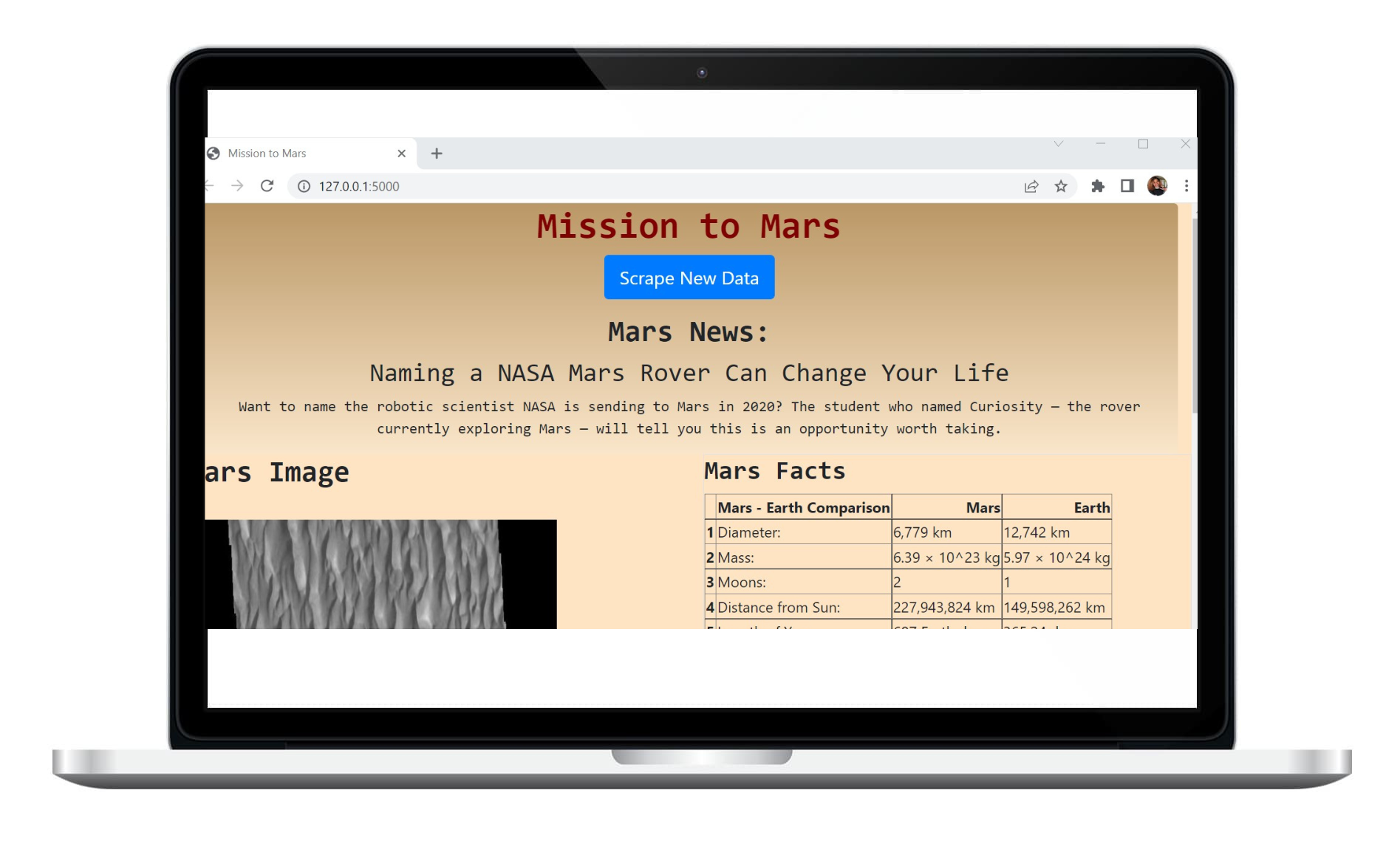
I completed my initial scraping using Jupyter Notebook, BeautifulSoup, Pandas, and Requests/Splinter. This had four parts: The Latest Mars News, Featured Mars Image, Mars Facts, And the Different Mars Hemispheres.Using redplanetscience.com, I scraped and collected the latest News Title and Paragraph Text and put them into two variables.Using spaceimages-mars.com, I used the Splinter module to navigate the site and find the image URL for the current Featured Mars Image, and assigned the URL string to a variable by combining what was scraped and the original URL.Using galaxyfacts-mars.com and Pandas, I was able to scrape the table containing facts about the Earth and Mars and converted the data to a HTML table string. Using marshemispheres.com , I obtained high-resolution images for each hemisphere of Mars by creating a For loop that captured both the image and the title. I stored them in variables.I converted my Jupyter notebook into a Python script called scrape_mars.py by using a function called scrape. This script scraped all of the data and was stored into a dictionary called mars_data. I connected my MongoDb and created a database mongo database titled mars_app and a collection titled mars_data. I then created a root route / that queried my mongo database to pass the data into an HTML template that displayed my data, using a HTML file called index.html.